
Er was dit jaar opvallend veel aandacht voor de risico’s van AI. De vraag is waarom we daar zo zenuwachtig van worden. Hoe komt het dat AI zoveel nieuwe vragen oproept?
In één van de meest bekeken leersnacks van de RijksAcademie voor Digitalisering en Informatisering Overheid (RADIO), gaat Tjerk Timan, onderzoeker bij de afdeling Strategy, Analysis & Policy van de Nederlandse organisatie voor Toegepast Natuurwetenschappelijk Onderzoek (TNO), nader in op deze vragen:
Een aspect van AI wat zeker daartoe bijdraagt, is volgens Tjerk Timan het feit dat AI eigenlijk een constant, niet aflopend experiment is.
“AI is een algoritme dat getraind wordt op data en vervolgens in de echte wereld met echte data aan de gang gaat, daar weer van leert en zodoende het model weer beter maakt en zodoende weer nieuwe data genereert et cetera.
Het moeilijke daarvan is ten opzichte van alle andere technologieën, ook digitale technologieën die we hebben, dat we eigenlijk voor het eerst in een wereld komen waar AI een soort van eeuwige bèta is. We weten niet goed hoe we op de lange termijn moeten nadenken over de effecten daarvan. Waar we vaak kijken rondom ethiek en technologie naar een bepaald product en soms ook wel naar een bepaald proces in een heel afgebakend veld, zie je dat AI zo breed kan worden ingezet en zo snel en ook globaal kan leren van nieuwe data en van nieuwe inzichten et cetera, dat het heel moeilijk is om te grijpen waar dat nou op zit.
Als we iets dieper gaan inzoomen over waarom dat eeuwige experiment zo problematisch is, zien we eigenlijk dat er een paar dingen zijn waar we op kunnen inzoomen.
Als eerste het feit dat we wel kunnen kijken naar het algoritme zelf en de data die erin gaat en waar het wordt toegepast, maar zodra AI in de echte wereld gaat leven, krijg je allerlei langetermijneffecten waar we eigenlijk nog nauwelijks goed grip op hebben.
Hoe, bijvoorbeeld, over de lange termijn, ontwikkelt een AI-model of algoritme zich aan de hand van nieuwe data? Doet het dan nog over tien jaar wat je in het begin beloofd had? Hoe zit het met de kwaliteit van data en van gegevens waar we die AI op trainen? En hoe zit het met echte-wereld-data? Hoe representatief is die eigenlijk? Et cetera.
Er is specifiek aandacht naar een bepaald aantal onderwerpen die vanuit de ethiek via de mensenrechten terechtkomen bij de AI-discussie. Eén heel belangrijke daarvan is gelijkheid, eerlijkheid en vooringenomenheid, wat ook wel bias heet.
![]()
Het moeilijke is dat we, omdat we heel veel processen zijn gaan digitaliseren, ook bepaalde waardes en vooringenomenheid meenemen in die data. Soms bewust, heel vaak onbewust. De geschiedenis van de manieren hoe wij data opslaan, worden gevangen in digitale middelen en data. En met die data gaan we algoritmes trainen, die vanzelf beter worden in het vinden van correlaties tussen die datasets. Dus zelfs al is die AI zo goed mogelijk geprogrammeerd, we krijgen toch een reflectie van de vooringenomenheid, de bias, in de maatschappij, in allerlei processen, krijgen we terug in AI.
Nou kun je zeggen: Wat is daar het probleem van? Die bias bestond al. Het probleem is dat we die bias zijn gaan automatiseren. Het is niet een mens dat daarnaar kijkt, of een groep mensen dat daar een oordeel over heeft of daartegen terug kan vechten, maar het is een algoritme dat zelf op basis van die data relaties gaat leggen en dat vooringenomen effect gaat versterken.
We hebben daar legio voorbeelden van, zoals bijvoorbeeld de COMPAS-casus in Amerika, waar een strafmaat werd bepaald door een rechter op basis van een algoritme. Dat algoritme was getraind op bepaalde data. In die data stonden bepaalde bevolkingsgroepen veel sterker vertegenwoordigd dan andere. Dus ging de AI zwaardere straffen toekennen aan die bevolkingsgroep. Daar is niks intentioneel verkeerd aan in het algoritme, maar je ziet de reflectie daar terugkomen.
Wat is daar een volgende stap in? Zelfs als dat algoritme eerlijk en transparant is – en zelfs al komen we achter dit soort problemen en fixen we ze, het is technologisch heel moeilijk om transparant te zijn over wat er gebeurt in zo’n algoritme. Vooral als het gaat over vormen van machinelearning waar een algoritme en een computer zelf gaat leren van bepaalde datasets, is het technologisch heel ingewikkeld om daar goed uitleg over te geven. Waarom komt een algoritme tot een bepaalde uitkomst? En kunnen we die uitkomst nog plaatsen in onze menselijke kennis en context?
En daarnaast, daaraan gekoppeld ook, de manier waarop we transparant moeten zijn. Is het publiceren van een algoritme transparantie? Of is transparantie de vraag over wat we met die uitkomst gedaan hebben, bijvoorbeeld? Dus over transparantie, en of dat technologisch moet zijn, organisatorisch of sociologisch, daar zijn nog heel veel discussies over. Daar worstelen we nog mee, hoe we nou eigenlijk aan de wereld kunnen uitleggen wat zo’n algoritme doet.
Dan is de vraag: Hoe kan de mens controle houden? Dat is nog een ethisch vraagstuk als het gaat om AI.

In heel veel algoritmes die we toepassen, zien we dat het vrij simpele algoritmes zijn, die we nog aardig goed kunnen uitleggen, zoals een regressieanalyse. Echter, we gaan naar steeds meer autonome systemen die in een split second een beslissing moeten nemen of een besluit moeten vormen en daarop moeten handelen. Denk aan een zelfrijdende auto of een cyberaanval op een elektriciteitsnet, bijvoorbeeld. Daar komt geen mens meer tussen. Daar hebben we geen tijd voor. En we hebben niet als individueel mens de capaciteit om dat allemaal te snappen en om met al die informatie om te gaan.
Dus in de context waarin autonome systemen zelf beslissingen maken rijst de vraag hoe we dan nog menselijke controle kunnen houden. En moeten we misschien die ethiek inbouwen in die technologie? Dat zijn huidige discussies die heel sterk leven in de technologische wereld, ook in de wereld van ICT. In hoeverre kun je en mag je regels en wetten inbouwen in de technologie, omdat de mens te langzaam is om te snappen wat je daar moet doen.
En als laatste zien we dat dat ingrijpt op een groot vraagstuk waar we nu in zitten, als we kijken naar de Gartner Hype Cycle van AI en ethiek, zien we dat we nu gaan van ethiek naar governance.

Hoe kunnen we die ethische vraagstukken in beleid en governance inbouwen? Hoe gaan we dat eigenlijk regelen? Daar komen dit soort vragen terug. Wie moet er toezicht op houden, bijvoorbeeld? Of: Hoe kunnen we zorgen dat die datakwaliteit goed is? Moeten we daar instanties voor oprichten, moeten we nieuwe wet- en regelgeving maken, et cetera.
We zien nu heel erg dat de vraag naast technologisch, rondom deze uitdagingen van transparantie en uitlegbaarheid en vooringenomenheid, nu zich ook vertalen naar de beleidskant en de managementkant. Hoe kunnen we eigenlijk AI goed managen?”
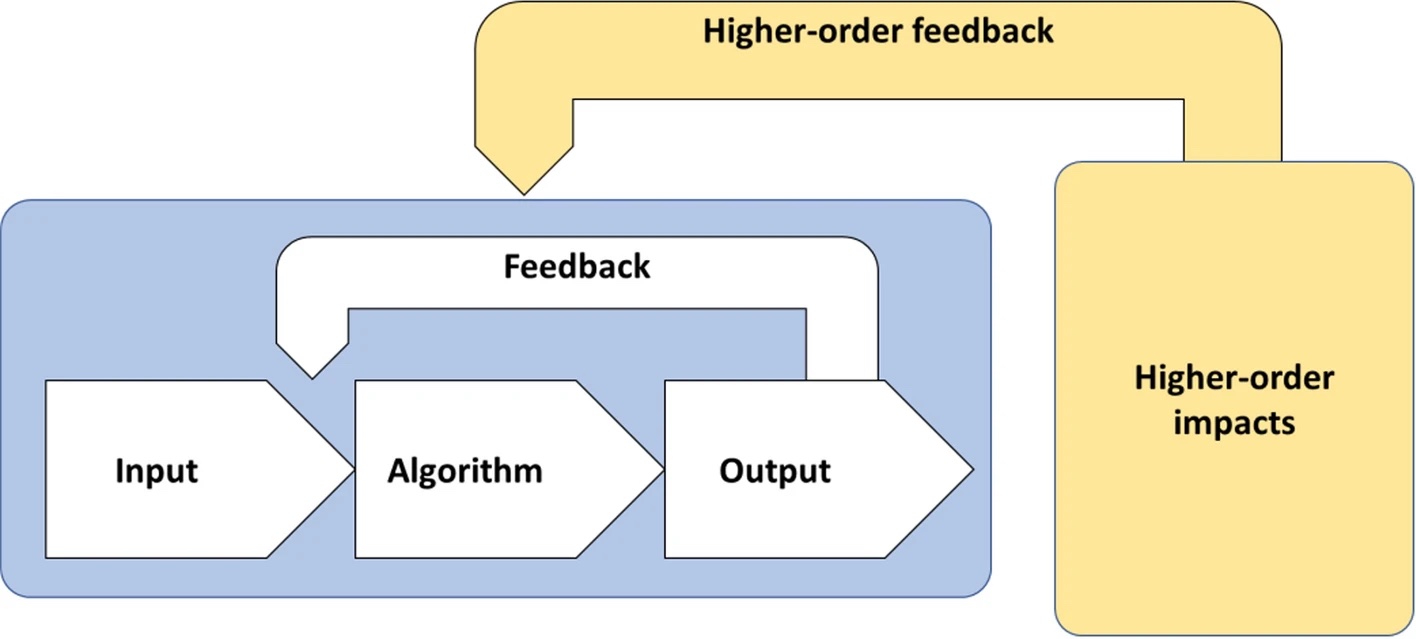
Als aanvulling op deze leersnack, verwijs ik graag naar het artikel ‘Responsible innovation, anticipation and responsiveness: case studies of algorithms in decision support in justice and security, and an exploration of potential, unintended, undesirable, higher-order effects‘ van Marc Steen, Tjerk Timan en Ibo van der Poel.
In het artikel richten de auteurs zich op het gebruik van algoritmes in het domein van justitie en veiligheid en meer specifiek op twee positieve voorbeelden van verantwoorde innovatie of responsible innovation (RI) in Nederland: het gebruik van algoritmes voor besluitvormingsondersteuning bij het Centrale Justitiële Incassobureau (CJIB) voor het innen van boetes en bij de Nationale Politie voor risicoanalyse van gewelddadig gedrag.
Bij het CJIB wordt een algoritme gebruikt om mensen te identificeren die risico lopen op verdere schulden en hen herinneringen of betalingsregelingen aan te bieden. Dit proces respecteert de autonomie van de medewerkers en de burgers, en richt zich op het voorkomen van schade door het minimaliseren van zowel vals positieve als vals negatieve resultaten. Het algoritme wordt gekenmerkt door zijn explicabiliteit, waarbij een relatief eenvoudige classificatiemodel wordt gebruikt dat begrijpelijk en uitlegbaar is voor zowel interne als externe belanghebbenden.
In het geval van de Nederlandse Politie is een algoritme ontwikkeld dat de waarschijnlijkheid van gewelddadig gedrag beoordeelt op basis van zowel gestructureerde als ongestructureerde data. Het doel is om politieagenten effectiever en efficiënter te laten werken door potentieel gewelddadige personen zorgvuldig en gepast te benaderen.
Deze studie benadrukt de complexiteit van het inzetten van algoritmes met betrekking tot de eerder genoemde hogere-orde-effecten. Het is essentieel om anticipatie en responsiviteit te integreren in het ontwerp en de implementatie van algoritmes om zowel de voordelen als de nadelen ervan te beoordelen.
De leersnack en het artikel laten duidelijk zien dat er naast de ethiek ook steeds meer behoefte is aan de beleids- en managementkant van AI.



1 reactie
Zie ook het LinkedIn-bericht van deze blog:
https://www.linkedin.com/posts/mderksen_waarom-worden-we-zenuwachtig-van-ai-koneksa-activity-7146201991478706176-NyTY